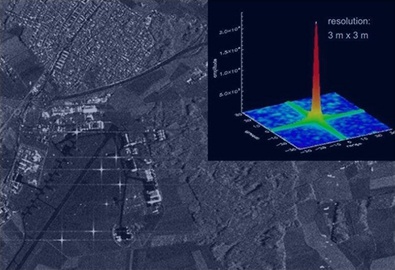
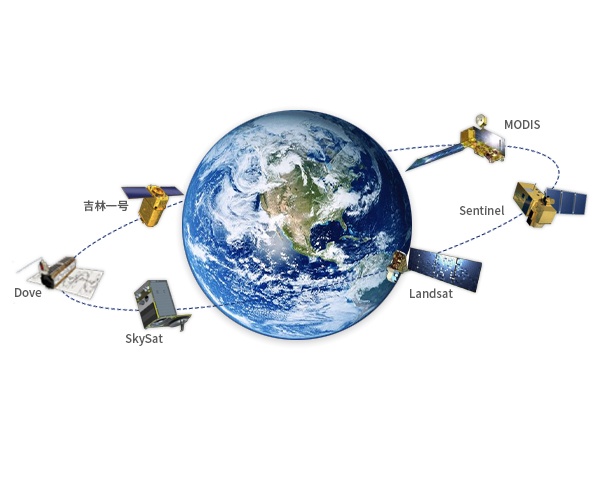
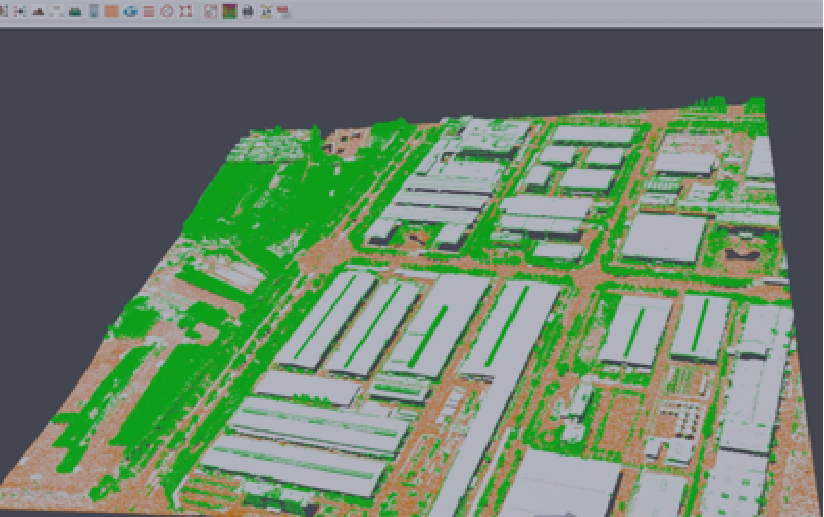
摄影测量的中心问题是从获取的影像来得到成像像素在影像中的世界点的三维坐标和语义属性的过程。其核心问题如下:
1、 如何建立相机和外部世界坐标之间的关系。这里需要两步:1)确定内参数;2)确定外参数。其中内参数用来描述相机在小孔成像过程中的一些重要参数值(焦距、主点、畸变...);外参数用来描述相机怎么摆在外部世界坐标系里(三个旋角组成的旋转矩阵,三个线元素组成的相机中心在世界坐标系的位置)。这个关系在 A)摄影测量的共线方程和 B)几何计算机视觉的投影方程里得以表达。从这里可以衍生的一点是,如果你知道外部世界点坐标,又能在影像上高精度定位出相应的成像点坐标,那么你就可以算出内外参数了,从而完成相机标定。当然,标定还有更多变种,但万变不离该宗。
2、 弄清了相机和外部世界的坐标关系怎么摆,接下来就要考虑怎么通过相片来算点坐标了。通过可能你已经发现,当你的外部世界坐标点在成像的光线上(即相机中心向像点发出的射线)来回窜动的时候,它对应的影像像点坐标是不变的!!这说明从物方点到像点的映射从线到点的对射,一条光线对应一个像点,所以需要加入第二张影像来交会确定出世界点的坐标。这引入了两个问题:1)两个相机之间的几何关系怎么表达?这是用相对定向模型(摄影测量)或者基础矩阵(计算机视觉)来表达的;2)怎么确定某个像点在另一张影像上的同源点(同名点/匹配点)?这个通过影像匹配来获取。 当几何关系被确定之后,通过前方交会就可以算两张影像上的同名点世界点的坐标。
3、 在2的基础上,要完成一片区域或者一个目标(建筑物、雕塑)的摄影测量,需要多张影像来完成。此时,可在刚才确定的相对定向的基础上进行连续的相对定向,即以某两幅影像相对定向的初始相机坐标系为参考坐标系,不断加入影像进行相对定向并放在第一幅影像表达的初始相机坐标系里面,所以进行完连续相对定向之后的坐标系还是初始的相机坐标系,由于相对定向的过程需要同名像点,所以实际上这个过程之后既得到了相机的姿态(位置、朝向),又得到了一部分用于定向的匹配同名像点在相机坐标系下的三维坐标(结构)。由于在这个过程中相机位置不断变化,形成了motion,所以这个过程在计算机视觉里又称为Structure From Motion(SFM)。把一系列影像都放在某个相机坐标下之后,此时通过少量地面控制点就可以把它与物方世界坐标之间的转换关系解算出来,完成绝对定向。这种思路称之为相对定向-绝对定向法。
通过以上的方法解算的过程一般都是渐进的,误差会不断积累和传播,为了提高精度,在最后会进行整体的再一次优化,优化的目标一般是最小化重投影误差。由于成像模型里的旋转矩阵是高度非线性的,这个优化问题是非线性优化问题,需要通过迭代来完成。通过迭代来优化的过程自然涉及到更新步长和更新方向(梯度)的问题,迭代步长和更新方向的确定用到了介于牛顿法(二阶梯度)和标准梯度下降(一阶梯度)之间的LM算法来完成,我们称这个过程叫光束法平差。
4、至此,你完成了把多幅影像对应的相机放到外部世界坐标系里,并在此过程中得到了一部分用于定向的匹配像点的3D坐标(稀疏定向点点云)。下一步就是密集地恢复深度,密集地测出影像上的点位坐标。以前我们叫立体匹配、多视立体匹配,现在匹配算法进步了,能逐像素匹配,我们干脆就叫它密集匹配了(Dense Matching)。其过程如下:
先生成核线影像,让视差集中到水平方向,也就是说一对核线影像上坐标(x1,y1)来说,它在对应的影像上的同名点坐标(x2,y2)总满足y1=y2. 所以你只需要去估计影像1上每个点的视差值x1-x2.注意,视差值决定深度(世界3D 点到成像平面的距离)。
每算一个可能的位置,都有一个匹配代价(交叉相关、互信息....),这样就形成了一个视差代价函数空间,它对应着影像1上每个像素取每个潜在可能视差值的匹配代价。

估计每个像素点的视差。这个估计的过程就是在取每一个视差值的时候,你就有一个匹配代价,这项称为数据项。同时,你还得考虑领域,也就是说当某个像素值与邻近像素相近时,我们也认为它们的深度更相近,如果他们的深度不相近,我们就惩罚它们;同理,当邻近像素的灰度值变化很大的,我们也认为它们的深度值倾向于有更大的变化,那么就会对灰度值变化很大而视差值差别不大的情况进行惩罚。完成这个惩罚设计出来的代价函数就是平滑项。平滑项和数据项一起构成了匹配优化的目标函数,也称作能量函数,最优化求解这个函数使得代价(cost)最小的解就是求解的每个像素的视差值。当然,有一部分点可能不能同时被两张影像看到(遮挡),这部分像素深度无法得到。
多个密集匹配的立体像对的结果进行融合,得到整体的视差值和三维点云。
5、干完这步,你可以开心的获取:
i) 数字地表模型
ii)数字正射影像
iii)获取 数字高程模型 DEM (要自动得把植被和建筑从DSM上分类出来剔除掉,然后插值格网化)
iiii)数字线划图 (还不是自动地
6、走到这里,我们做的还是几何问题。那么语义属性在哪里呢
属性通过分类来算。输入值是影像(可加入深度)(或特征),输出值是类别,中间过程用监督学习下的分类器来完成。或者用非监督学习压缩数据,然后用监督学习得到分类器。
属性怎么算呢?如果用上我们辛辛苦苦得到的深度值,那我们依靠的还是马尔提出的视觉问题框架,通过深度值为跳板来解决视觉问题。现阶段以我的知识,能理解到的需要解决的核心问题是:
如何设计出好的特征,这里面又分为采用经典的手动设计特征和现在火热的基于深度神经网络的自动特征表达学习,其核心问题是找出区分力高的特征表达。
如何表达先验,如何融合已有的知识,如GIS数据库、地图等信息,如何融合多平台的测量数据(卫星影像、航空影像、地面车载数据,UAV数据以及网络大数据)。
不同地区的训练数据往往类别规定和类别分布不一致,如何有效的统一和迁移学习到的知识;以及如何建立高效海量的数据库来加速这一领域的发展。这个问题还是现在进行时。
7、 航空影像的分类解决好了,还是土地的覆盖分类,土地的利用类别呢?国土资源的管理、地图的制作依靠的是土地的利用类别(荒地可能是荒地,可能是闲置的商业用地,这区别太大了)。解决这个问题一方面需要加入合理的先验;另一方面需要更加先进的分类模型和大数据的支撑。

ADS系列数字航摄仪应用的是推扫式摄影方式,应用POS系统进行数字影像获取。在航空摄影测量中应用ADS系列数字航摄仪,可以不经过扫描便可以直接为遥感图像处理系统及数字摄影测量提供全色...

金秋十月,华夏中原,中国测绘学会主办的中国测绘地理信息科学技术年会10月16日-17日在...

与传统的测绘技术相比,高空摄影技术可以对高空大比例尺的地形图进行较为准确的测绘。...

航空摄影测量技术中的空中三角测量,是在立体摄影测量实践中参照少部分野外控制点,并...

作为一种通过空间数据得到核心技术处理的综合技术,技术应用过程中需要从技术层面分析...
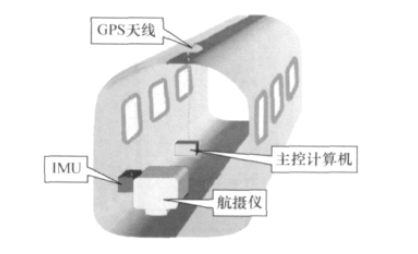
POS辅助空中三角测量的第一步是要采用载波相位动态GPS定位技术测定摄站的空间位置(简...

电话:025-83216189
邮箱:frank.zhao@feiyantech.com HR@feiyantech.com(人力资源)
地址:江苏省南京市玄武区红山街道领智路56号星河World产业园3号楼北8楼

微信公众号

总经理微信
版权所有:飞燕航空遥感技术有限公司 © 2019 备案号:鄂ICP备19029994号-1 苏ICP备20022669号-1  鄂公网安备:420106020021194号
鄂公网安备:420106020021194号  简体中文/English
简体中文/English